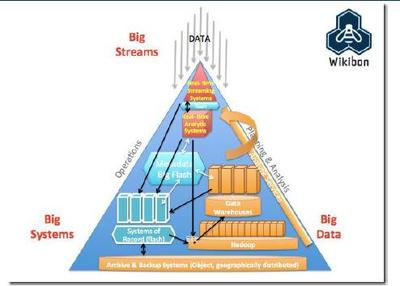
在当今数字化浪潮中,数据已成为驱动社会进步与经济发展的核心要素。大数据的兴起,正是得益于其背后三大基础技术支柱——计算、存储与分析技术的持续演进与成熟。这些技术相互促进,共同构建了支撑海量数据处理与应用的技术底座。
一、计算技术:从集中到分布,从通用到专用
计算技术是大数据处理的引擎。早期,数据处理主要依赖于大型机或高性能服务器的集中式计算。随着数据量的爆炸式增长,这种模式在可扩展性和成本上遇到了瓶颈。以Hadoop MapReduce、Spark为代表的分布式计算框架应运而生,它们能够将计算任务分解并分发到成百上千台普通服务器组成的集群中并行处理,极大地提升了数据处理能力。
计算技术进一步向异构和专用化发展。图形处理器(GPU)、张量处理单元(TPU)等专用硬件被广泛应用于机器学习、深度学习等对算力要求极高的数据分析场景,显著加速了模型训练与推理过程。云计算提供的弹性计算资源,使得企业能够按需获取近乎无限的计算能力,降低了大数据应用的门槛。
二、存储技术:容量、性能与成本的平衡艺术
存储技术负责承载海量数据。传统的关系型数据库在面对非结构化、半结构化数据以及高并发读写时显得力不从心。分布式文件系统(如HDFS)和NoSQL数据库(如HBase、Cassandra、MongoDB)的成熟,解决了海量数据存储与高可扩展性的问题。它们能够在廉价硬件上构建起可靠的存储集群,并通过数据分片、副本机制保障数据的安全与可用性。
对象存储(如Amazon S3、阿里云OSS)因其极高的扩展性、耐用性和低成本,已成为存储海量静态数据(如图片、视频、日志)的事实标准。新硬件如固态硬盘(SSD)、非易失性内存(NVM)的普及,以及存储与计算分离架构的流行,都在持续优化着数据存取的性能与成本结构。
三、分析技术:从离线批处理到实时智能洞察
分析技术是大数据价值变现的关键。早期大数据分析主要以Hadoop MapReduce为代表的离线批处理为主,处理延迟通常在小时甚至天级别。Apache Spark凭借其内存计算优势,将批处理性能提升了一个量级。
业务对实时性的追求催生了流计算技术的快速发展,如Apache Flink、Apache Storm和Spark Streaming,它们能够对持续不断的数据流进行毫秒级到秒级的处理与分析,使得实时风控、实时推荐等应用成为可能。
更重要的是,分析技术正与人工智能深度融合。机器学习平台和深度学习框架(如TensorFlow、PyTorch)的成熟,使得从大数据中挖掘复杂模式、进行预测和决策变得更为高效和普及。交互式查询引擎(如Presto、ClickHouse)则让用户能够以接近传统数据库的速度对海量数据进行即席查询与分析。
四、计算机软硬件的协同进化
大数据技术的成熟离不开底层计算机软硬件的协同进化。在硬件层面,多核CPU、大内存容量、高速网络(如RDMA)以及前述的GPU、SSD等,为数据处理提供了强大的物理基础。在软件层面,虚拟化、容器化(如Docker、Kubernetes)技术实现了资源的精细化管理和高效调度;而各类开源大数据软件构成的庞大生态系统,则加速了技术的迭代与创新。
****
计算、存储、分析三大基础技术的不断成熟与融合,以及软硬件的协同优化,共同推动大数据技术栈日趋完善和高效。从离线到实时,从感知到智能,大数据技术正不断突破性能、规模和易用性的边界,赋能千行百业的数字化转型,挖掘数据中蕴含的无限价值。随着量子计算、存算一体等新技术的探索,大数据的基础技术体系将继续演进,迎接更大规模、更复杂场景的挑战。